
Who owns a patient’s health data?
Per the U.S. HIPAA privacy law, it’s not the patient but the provider. The U.S. Department of Health & Human Services (HHS) explicitly doesn’t require patient consent for health data that would normally be protected under HIPAA to be used for research—if it is de-identified.
So, providers absolutely can and do offer and even sell patient data for research and AI training. How you feel about this may depend on where you sit in the medtech landscape.
On one hand, organizations and companies being able to use de-identified patient data for research is a massive boon for healthcare. On the other hand, ensuring that data is truly de-identified and managing the ethics therein is a tricky business.
Medtech startups have taken up this task. Notable players in the de-identified health data space include:
- Truveta — a company selling various types of health data, which also recently announced a project to create a massive database of genetic data paired with health record data
- Avandra — offers researchers access to medical images and associated patient data while also advertising to providers that they can earn “passive income” by selling their patients’ EHR data and imaging to the company
- Gradient Health — a data company granting researchers access to medical imaging
- Segmed — offers medical imaging data for clinical research and AI training
While these companies reinvent what we can do with patient health information, patient advocates are wondering: How do patients feel about this? Are patients signing consent documents because it’s the only way to access care? Or do they hope their de-identified data helps others?
It depends on who you ask. While studies have been done to ascertain patient opinions on the use of their health data for research, opinions can vary between populations.
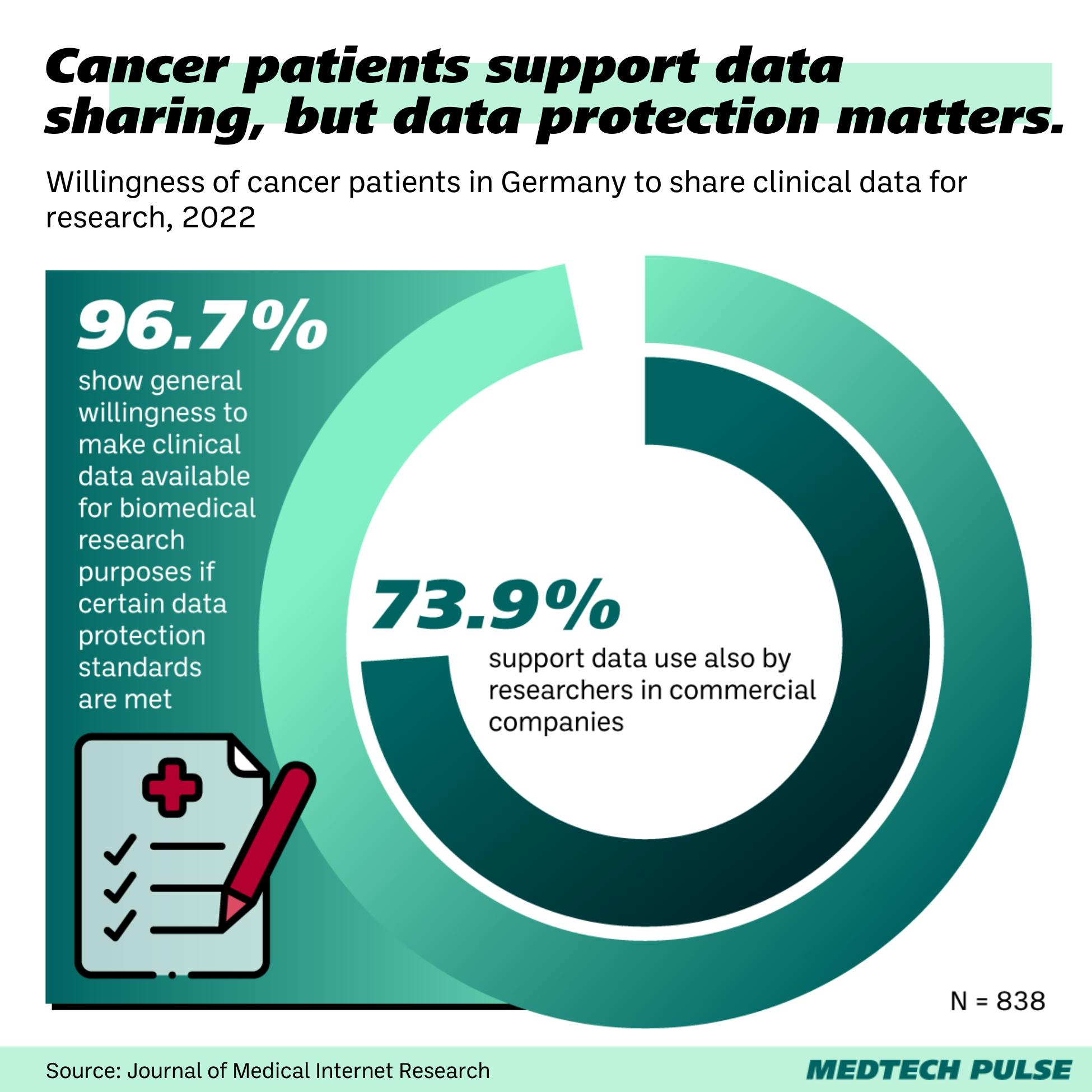
However, one thing is clear from this research: Even when patients are enthusiastic about their data being used to further health research, this depends on that data being thoroughly de-identified.
How does HHS ensure that data is properly de-identified? There are two main methods:
- The cookbook method — where a checklist of 18 specific identifiers must be redacted
- The expert determination method — where HHS-designated experts redact the data and designate it as de-identified
There are added complexities to how companies and institutions use one or both of these methods in preparing patient data for research use. For instance, they must balance the need to keep a patient’s data anonymous while maintaining its usefulness by pairing data from different types of datasets together.
What is clear is that, for AI models trained on patient data to be most effective, they require access to these large amounts of de-identified data. We need to keep balancing this need for technological progress with continuous evaluation of whether our methods truly serve patients and their right to privacy.
I’m excited to see what these ambitious health data startups continue doing with health data. We owe it to patients—and future patients—to put it to good use.
